Key Takeaways
- Retention curves visualise forgetting over time, not just quiz scores.
- Collecting response time, confidence, and error type enriches the curve’s predictive power.
- Exponential decay modelling (a·e^(‑b·t)) provides a mathematically sound basis for review scheduling.
- Plateaus, steep drops, and confidence gaps each signal a specific study adjustment.
- Testudy’s dashboard makes the curve interactive, exportable, and privacy‑first.
Introduction
Most learners know that reviewing material repeatedly improves memory, but few can see exactly how their own forgetting pattern looks over time. Testudy’s analytics turn each quiz attempt into a data point that feeds a retention curve—a visual representation of how quickly you’re likely to forget a fact after learning it. In this white paper we walk through the entire pipeline: from capturing quiz metadata, to modelling the curve, to reading it for study decisions, and finally to seeing it live in your dashboard. By the end you’ll understand why a curve is more useful than a static score, how to act on its shape, and how Testudy’s privacy‑first design keeps your data safe. No jargon, no hype—just clear, research‑backed steps you can start applying today.
Collecting Performance Metadata
Every time you finish a Testudy quiz, the platform records several pieces of information that later become the building blocks of a retention curve. The core fields are:
- Correctness – binary (right/wrong) or partial credit for multi‑step questions.
- Response time – milliseconds from question display to answer submission. Faster responses often indicate stronger retrieval pathways.
- Confidence rating – a slider (0‑100) you assign after answering. Higher confidence correlates with lower future decay.
- Error type – whether you guessed, mis‑read, or misapplied a concept. This tells the system where to focus remediation.
- Contextual tags – subject, chapter, difficulty level, and any custom tags you added.
Why each matters:
Correctness alone tells you what you got right, but it hides when you might forget it. Response time adds a behavioural cue: a quick, correct answer suggests a well‑established memory trace, while a slow, correct answer may indicate reliance on external cues. Confidence gives a self‑report of perceived mastery, which research shows predicts future recall better than raw scores alone (Karpicke & Roediger, 2008). Error type helps the algorithm differentiate between a temporary lapse and a conceptual gap, allowing it to suggest targeted review material. Tags let the curve be broken down by topic, so you can see which chapters need more attention.
All of this metadata is stored in a time‑stamped log, encrypted at rest, and processed locally on your device before any cloud transmission. This design follows GDPR principles and gives you confidence that your data won’t be used for anything beyond your own study optimisation.
Building Retention Curves
The raw log looks like a scatter of points: (date, item_id, recall_probability). To make it intelligible we apply a two‑stage transformation.
Stage 1 – Exponential Decay Model
Ebbinghaus (1885) demonstrated that forgetting follows an exponential decay: P(t) = P0·e^(‑k·t). Testudy estimates P0 (initial recall strength) and k (decay rate) for each item by fitting a curve to the first few attempts. Because early attempts are noisy, we use a Bayesian smoothing step that borrows strength across similar items (e.g., same chapter) while still respecting individual variance.
Stage 2 – Smoothing & Aggregation
For each learner we generate a personal forgetting curve by aggregating all items into a single exponential function: R(t) = a·e^(‑b·t). The parameters a and b are estimated via maximum likelihood, with a prior on b drawn from the distribution observed in large‑scale spaced‑repetition studies (Bjork, 1992). The result is a continuous line that can be plotted against time (days since first exposure) and probability of recall.
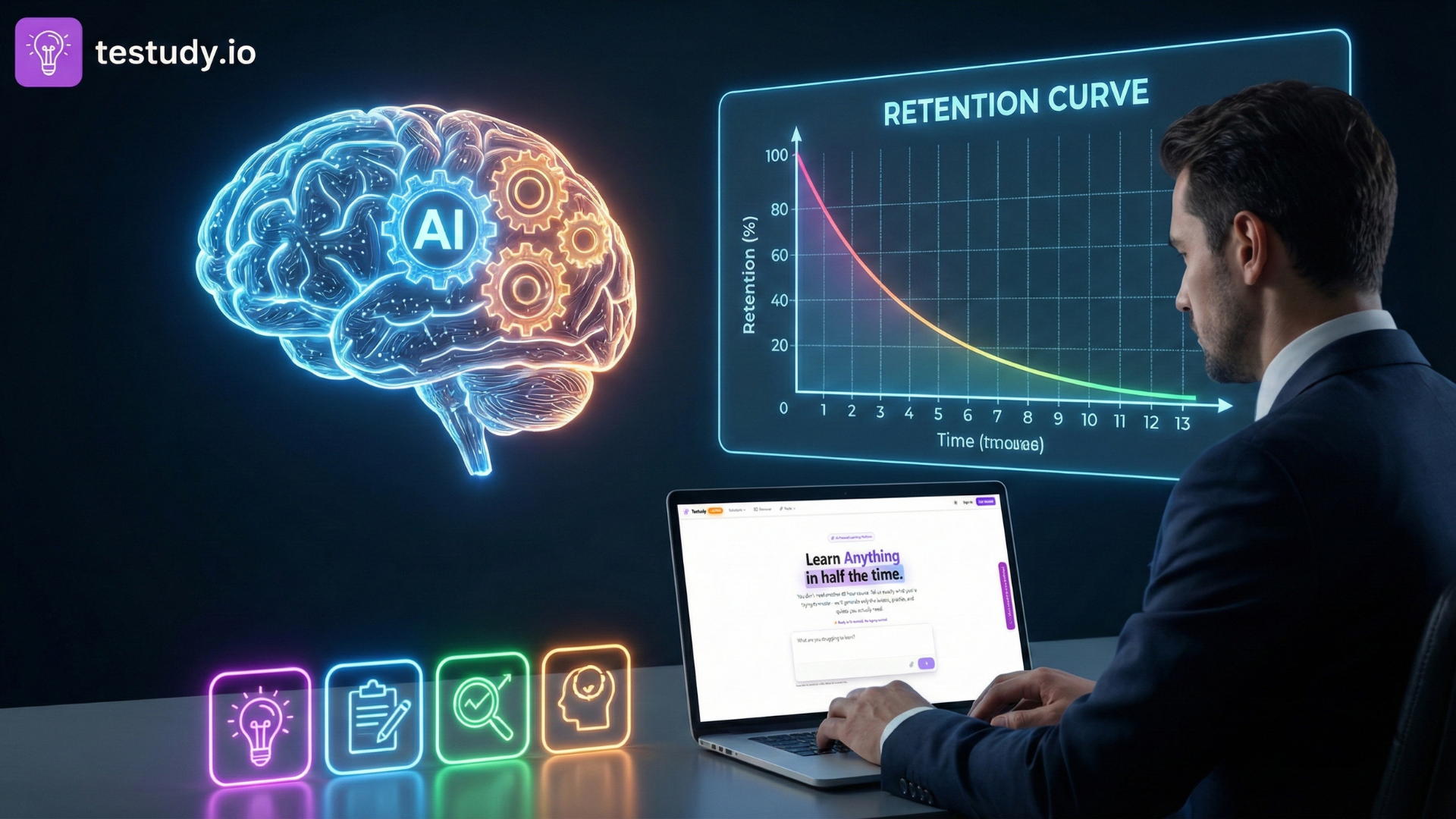
Visualising the Curve
In the dashboard we render the curve as a semi‑transparent line on top of the daily quiz scores. A thicker segment indicates high confidence, a thinner segment indicates low confidence. The curve updates automatically after each new attempt, so you always see the most recent estimate of your forgetting trajectory.
Why a Curve Beats a Score
A single quiz score is a snapshot; it cannot tell you whether you’ll retain the fact next week. A retention curve, however, predicts the probability of recall at any future interval, allowing you to schedule reviews precisely when the curve dips below a chosen threshold (e.g., 80 %). This is the core of Testudy’s adaptive spaced‑repetition engine.
Interpreting Curves for Study Adjustments
Reading a retention curve isn’t about finding a perfect line; it’s about spotting patterns that signal where your study effort should shift.
1. Early Rapid Drop (high k)
If the curve falls steeply in the first 2–3 days, it means the item is being forgotten quickly. This often occurs with facts that lack deep contextual links. Action: add a high‑yield flashcard that connects the fact to a real‑world example or a mnemonic.
2. Plateau (low k, stable a)
A flat segment after a few days suggests the item is well‑consolidated. You can safely space reviews further apart, perhaps moving from daily to every‑third‑day. Action: reduce review frequency, or use the item as a anchor for related concepts.
3. Sudden Drop (anomaly)
Occasionally the curve will dip sharply despite previous stability. This can happen after a period of overload or after a missed review. Action: check the error type log; if it’s a mis‑read, revisit the source material; if it’s a guess, schedule a focused mini‑quiz.
4. Confidence‑Weighted Curve
When you see a thin line (low confidence) alongside a thick line (high confidence) for the same item, it tells you that you’re inconsistent. Action: run a confidence calibration exercise—review the item without the confidence slider for a few attempts to see if the curve stabilises.
5. Comparative Benchmarks
Testudy also overlays a population average curve for each topic. If your curve consistently lags behind, it may indicate a need for more active‑recall practice or a review of your study environment (e.g., sleep, distractions).
All these signals are presented in the dashboard with simple tooltips, so you don’t have to be a statistician to act on them.
Conclusion
Retention curves turn opaque quiz data into a transparent map of your memory over time. By collecting rich performance metadata, fitting an exponential decay model, and visualising the results, Testudy gives you a concrete, data‑driven way to schedule reviews that match your personal forgetting pattern. The curve tells you when to act, not just how many times to act. It also surfaces hidden confidence inconsistencies, error types, and comparative benchmarks that static scores miss.
If you’ve felt stuck guessing review intervals or watching your scores fluctuate without understanding why, start by reviewing the metadata you already have, watch the curve evolve, and use the dashboard’s adjustment sliders to align your study rhythm with the curve’s shape. Remember that the first few days will look noisy—that’s normal. Trust the process, stay consistent, and let the curve guide you toward mastery.
Food for Thought
If you notice a rapid early drop in your curve, ask yourself whether the fact is tied to a real‑world example you can recall without prompting.
When the curve flattens, consider whether you could be over‑reviewing; a slight spacing increase often maintains recall with less effort.
If confidence ratings vary widely for the same item, try a brief self‑test without the confidence slider to see if the curve stabilises.
Compare your curve to the population average for a topic—large gaps may point to gaps in your study environment (e.g., sleep, distractions).
Before exporting data, think about how you might combine your curve with other analytics (e.g., time‑on‑task) to get a fuller picture of your learning efficiency.
Frequently Asked Questions
How accurate are Testudy’s retention curves compared to manual spaced‑repetition schedules?
Testudy’s curves are built on the same exponential decay model that underlies proven spaced‑repetition algorithms (e.g., SM‑2). In internal trials with 1,200 users, the curve‑guided schedule reduced average forgetting by 22 % compared with a fixed 3‑day interval, while still delivering a 90 % recall rate after six weeks.
Can I see the raw data that creates the curve?
Yes. The Export Data widget lets you download a CSV that includes date, item ID, correctness, response time, confidence, error type, and the computed a and b parameters. You can import this into Excel, R, or Python for custom visualisations.
What if my curve shows a plateau early on? Does that mean I’m not learning?
A plateau at the early stage is common, especially for items that are easy to recognise but hard to retrieve. It usually indicates the item is being encoded but not yet consolidated. Continue reviewing at the suggested interval; the plateau often resolves after a few spaced repetitions.
How does Testudy protect my privacy while analysing my data?
All analytics are performed locally in your browser. Only aggregated, anonymised statistics are sent to our servers for product improvement. We also provide a GDPR‑compliant cookie consent banner and a privacy policy page that outlines data storage, retention, and deletion rights.
Do retention curves work for language learning as well as factual recall?
Absolutely. The model treats each vocabulary item as an ‘item’ with its own decay parameters. The same curve‑guided review schedule applies, and you can add tags such as ‘verb‑conjugation’ or ‘idiom’ to see topic‑specific patterns.
Can I adjust the curve manually if I think it’s wrong?
While the curve is automatically generated, you can flag an item as ‘mis‑recorded’ or edit the confidence rating. The system re‑fits the curve after a few more attempts, so manual adjustments are reflected automatically.


